Given circumstances: you’ve been amassing an arsenal of irreverent web-based imagery (since before the term “meme” was collectively used to describe them and let’s split semantic hairs over this later).
The problem: something has jarred a memory of one of those, let’s conservatively estimate, 100,000-odd images and you suddenly feel that burning animal need to find and share that image (and using Google Images would just be cheating).
So you need to come up with a system of cataloging, sorting, tagging, or otherwise just discriminating between images in a more efficient manner than flipping through endless lists of thumbnails. There are a few curve balls, of course — these images run all of the gamuts from small to large, from static to Peter-Jackson-movie-length, from run-of-the-mill JPEGs to static and animated GIFs to PNGs with, I don’t know, maybe a TIFF thrown in here and there for good measure. The category/tagging system needs to be portable and future-proof. The system needs to run more or less autonomously, as hand-holding through each image run — or even through batches of images from the same source — is too tedious (and inelegant) to entertain. While I have a few different operating systems at my disposal, the bulk of the effort will be spent on my Windows 10 machine, so it’ll need to operate within that system (in retrospect, if I had a more robust Unix box than my Raspberry Pi, it would’ve been an ideal choice). The cost should be kept minimal or, for all practical purposes, nil. And, ideally, you should learn something in the process.
The solution — current solution, really, as this is pretty clearly an evolving process which will benefit from enhancement and refinement as time goes on — is a hybrid of quite a few different free software packages: Darknet, YOLO9000, Tesseract, ImageMagick, and ExifTool. Individually each is a tool — at least useful, at most invaluable — together they work wonders.
First up, Darknet. Darknet runs in C, is compatible with CUDA to take advantage of whatever graphics card power you have at hand, and is relatively simple to compile and get running. …Well, not so much if you’re operating in Win10, even with the enhanced Unix-ish tools Microsoft has been letting drip into the OS. Compilation has been tricky, and since I have just a sliver of hard disk space left, installing and compiling with CUDA hasn’t been remotely possible (though I should be getting a new hard drive to alleviate this today). Still, even running purely under the CPU, this implementation of Darknet is a fire-and-forget solution, so an extra 10-30 seconds per image isn’t a deal-breaker.
While Darknet does the actual computation and image processing, YOLO9000 is the engine’s visual dictionary, the information that ties a certain blob of pixels to a label (“shetland pony” or one of 9418 other classifications, whereas Darknet’s default dataset has only 20). There’s always going to be a trade-off between the size of your label set and performance, but YOLO, and YOLO9000 in particular, seem to inhabit the sweet spot, the balance point between complexity and performance.
It should also be noted that image recognition/identification is only one part of this solution — what do we do when a significant percentage of these images to be catalogued are Twitter/Facebook screenshots? Ideally, I’d like to have an optical-character recognition feature, one that can take an image of text and turn it into searchable text. And that’s where Tesseract comes in. Tesseract is the gold standard for open-source OCR, and it really needs no help at all to give you solid, useful results. With just the slightest bit of image tweaking, you can enhance the quality of the text recognized and returned, which brings us to….
ImageMagick is a suite of image-processing tools fired from the command line, something that doesn’t sound all that useful on first examination, but its utility becomes more evident the more roadblocks you run into during development. If you want to adjust an image’s levels and contrast (to, say, make an image more readable by Tesseract), ImageMagick makes it happen. Need to bounce an image between formats, resize it, add text, combine images…? It’s Photoshop for the command line, with all the utility and waterfall of features that implies.
ExifTool is another command-line utility with an overwhelming feature set that solves problems you never realized you had. ExifTool interfaces with a feature embedded in some digital images called the Exif tag — most of the time this is a handy way of extracting data about a digital photo, anything from its dimension or bit depth to even a geotag if you need to know precisely where the image was taken. For our purposes, it’s just important to know that these Exif tags are (a) only for JPEGs and some TIFFs and (b) can be read, modified, and indexed natively by Windows. And that’s the last bit of information that ties everything together.
The process that binds all of these systems together is nothing more complicated than a hundred-line (well, 30% is comments) batch file. Drag and drop up to 100 images (this is a limit I’ve run into and can’t seem to get around yet but I’ve had bigger fish to fry) onto it, and each image will fall into this algorithm:
- Is the image a JPEG file? If not, create a JPEG of the image and use it as the work file. If the original is an animated GIF file, it pulls off the first frame of the GIF to use as the work file.
- If it doesn’t already exist, create a “results” folder in the folder where the original image came from.
- Copy the image to a Darknet work directory. (Darknet has an issue with a relative link in its code that needs fixing — without it, it’s going to cause problems finding label images if you try to run Darknet outside of its home directory.)
- Run Darknet — using the YOLO9000 image weights file — on the work image, outputting the detection results to a text file.
- Check the “predictions.png” file Darknet should’ve created with the image labels and bounding boxes shown on it. If it’s the same size as “predictions.png” was before Darknet was run, then Darknet probably crashed, so skip to the next image.
- Translate “predictions.png” to a JPEG version in the “results” folder and rename it to match the original image.
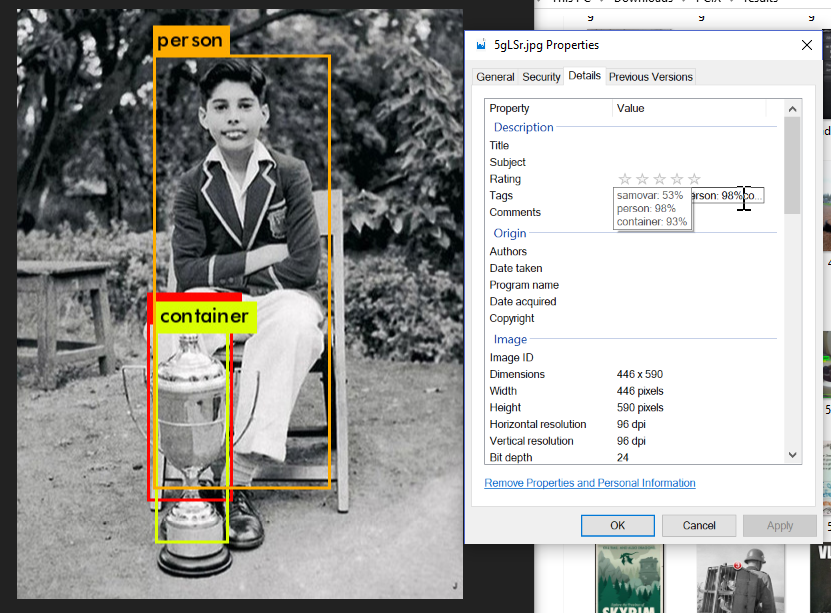
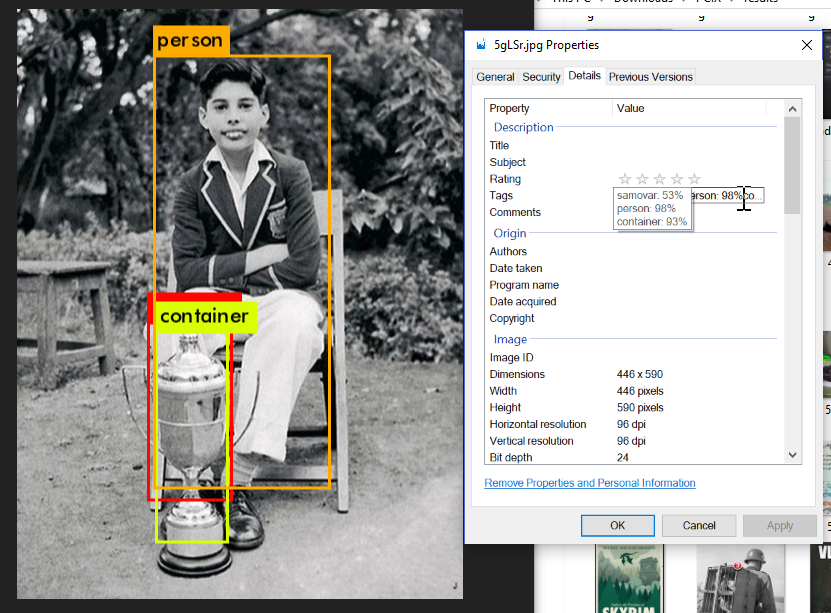
- Take the list of identified objects (which Darknet output to that text file when it ran) and embed the results in this new JPEG file under the “XPKeywords” Exif tag so it shows up in Windows.
- (Optional, but right now, implemented: take that text file and embed it into the Exif tags of the original image.)
- Take the work copy of the image and feed it through Tesseract and into another text file, returning every character Tesseract found (or thought it found) in the image.
- Embed that text file into the “XPComment” Exif tag of the file in the “results” folder.
- (As above, optional, but right now, implemented: take that text file and embed it into the Exif tags of the original image, too. Now, regardless of what happens to the “results” folder or the contents therein, you’ve got the original image tagged with the image-recognition items and the OCR text.)
- Clean up all of the extraneous text files, just for decluttering’s sake.
- Move on to the next image.
And now, if all’s gone well, you should have a whole slew of images with tags and text searchable from the Windows Explorer interface.
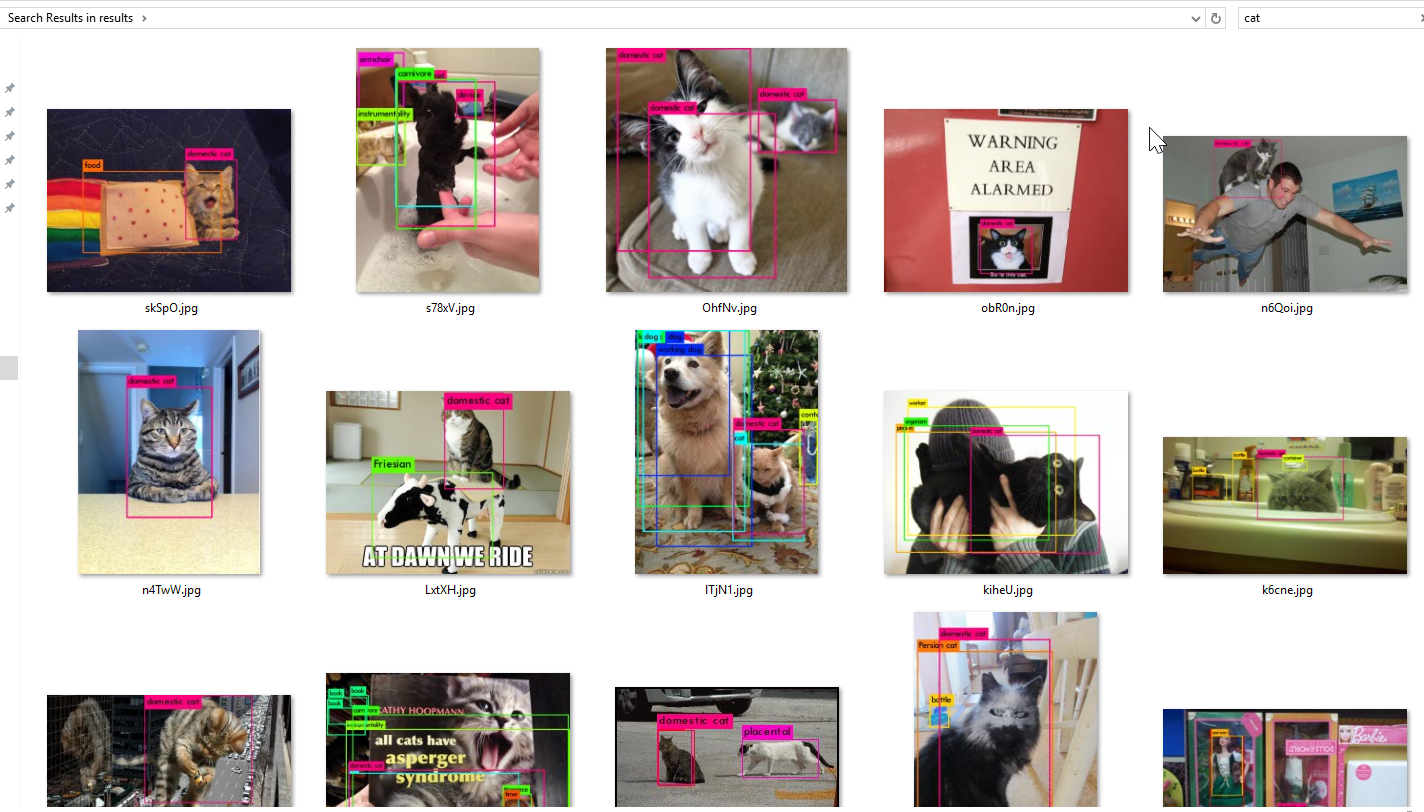
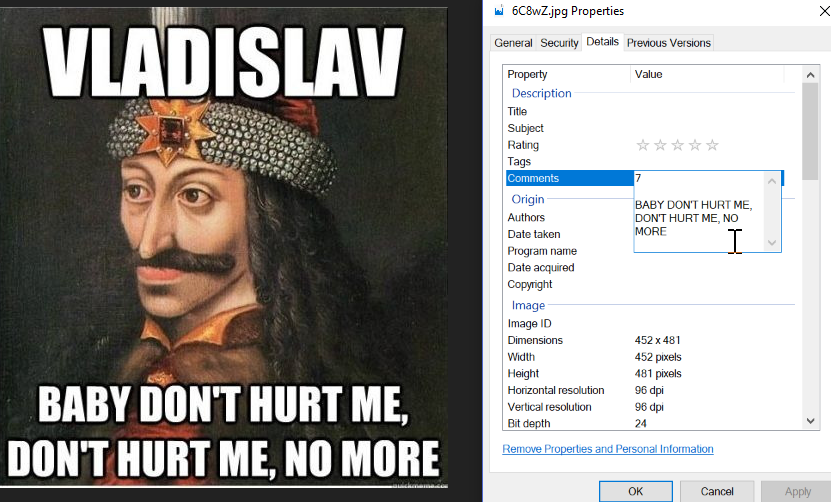
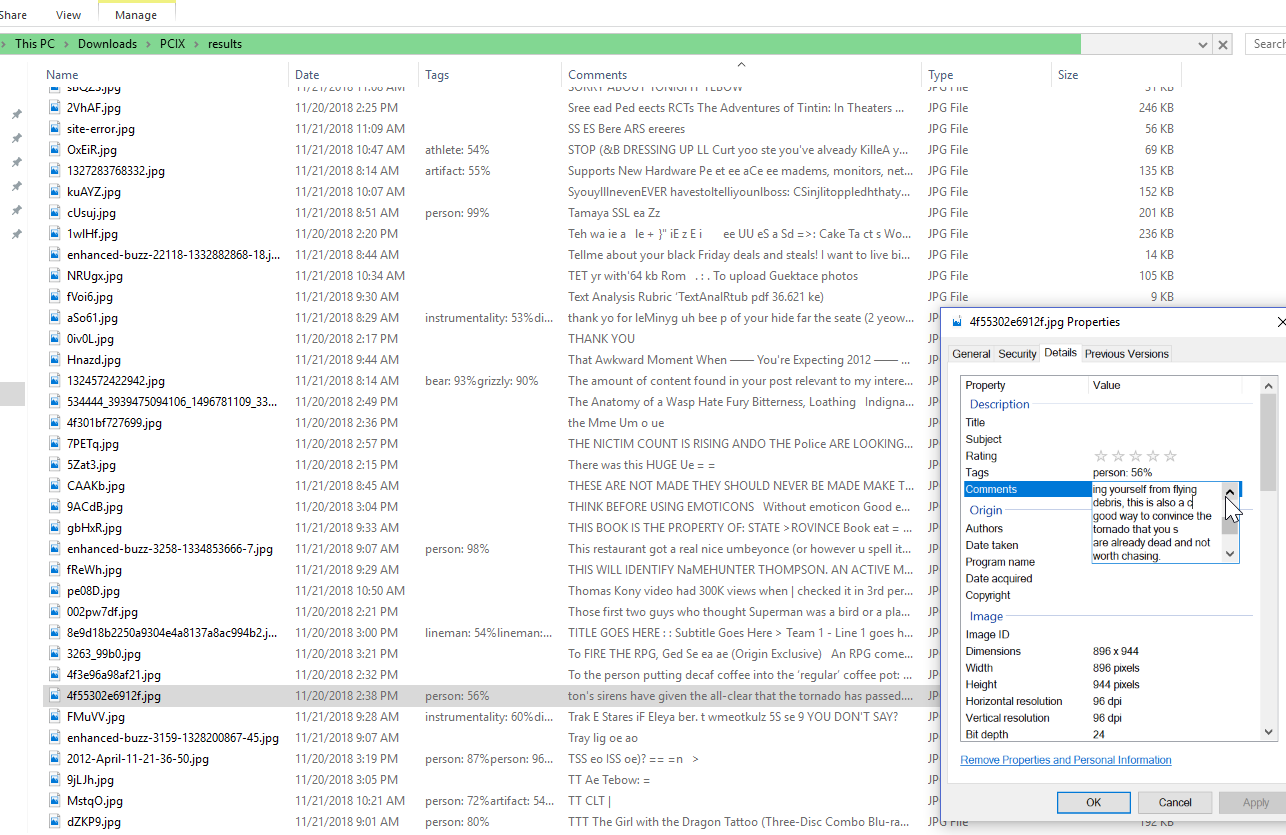
I highly recommend toying around with any and all of these pieces of software, and finalizing their interplay and integration will give you a genuine sense of accomplishment. And now when you’re looking for that newspaper story about convincing a tornado you’re already dead — there it is!

