
Observation: it’s cold outside. Update: I’ve fully emigrated from...
Tiny

Am still on Twitter for reasons that really escape...
I had ChatGPT generate some lorem ipsum for a...

My favorite sub-genre of fiction nowadays is “What if...

New theme! Hold your gasps of approval, please. Moving...

Still alive! Not especially thrilled about it, but that...

Would you believe…a picspam?

Well, that’s not true, of course. Everything’s happened. The...

I could tell you what spurred the creation of...
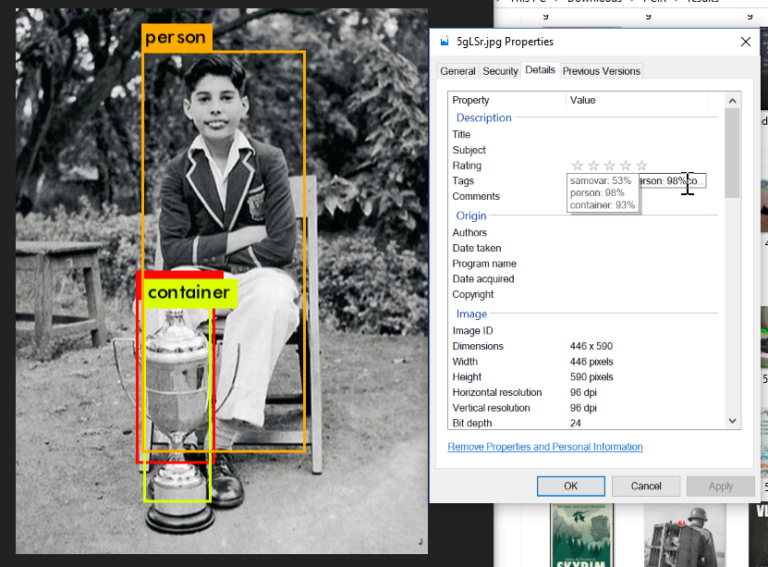
Given circumstances: you’ve been amassing an arsenal of irreverent...